Every day, AWS Lambda runs trillions of function invocations. AWS Fargate schedules millions of containers. Every one of those is a full virtual machine, with its own kernel, booted in a fraction of a second.
How? About 50,000 lines of Rust called Firecracker, which exists because the industry finally admitted that a Linux container that controls resource usage was never designed to be a security boundary.1
The isolation problem
Every Docker container on your laptop is three Linux kernel features in a trench coat:
- Namespaces are blindfolds. A process inside one gets a private view of the system: its own PID list, network stack, mount table, hostname, and user IDs. PID 1 inside the container is some random PID on the host; the container can't even see the other processes.
- cgroups are budgets. Control groups are the kernel's accounting and rate-limiting layer. They cap how much CPU, memory, disk IO, and network bandwidth a process tree is allowed to consume.
- seccomp + capabilities are allowlists.
capabilitieschop root's powers into ~40 separate privileges (bind low ports, load kernel modules, mount filesystems, etc.) so you can grant only the ones you need.seccompis a per-process filter that decides which syscalls (userspace's only API into the kernel) the process is even allowed to make.
You can prove it yourself without Docker installed:
# spin up your own "container" in one line
unshare --user --map-root-user --mount --pid --net --uts --ipc --fork --mount-proc bashEverything else Docker does (image layers, registries, DNS) is orchestration on top.
All of that protection funnels through a single Linux kernel, around 30 million lines of code exposing 400+ syscalls. Every container on the host calls into that same kernel. One bug in any one of those syscalls and it's game over for every tenant on that machine.
Full virtual machines solve isolation by brute force: every VM gets its own kernel.
Modern CPUs have a "guest mode" that runs guest instructions on the real silicon. The host only gets pulled in when the guest does something privileged (touches real hardware, faults, gets interrupted). A hypervisor is the thin layer that arbitrates those moments.
Linux ships its hypervisor as a kernel module called KVM, exposed at /dev/kvm. It rides on hardware virt extensions (vmx on Intel, svm on AMD):
# do you have hardware virt?
grep -E 'vmx|svm' /proc/cpuinfo | head -1
ls -l /dev/kvmThe problem with full VMs is they're slow and fat. A classic QEMU VM emulates a whole imaginary PC (BIOS, PCI bus, IDE controller, VGA card, PS/2 keyboard) because that's what a 1998 OS expected to boot against. The image is hundreds of megabytes. Boot takes seconds. Memory footprint is hundreds of MiB before your workload even starts. For a web request that lives 40ms, you'd spend 40× that booting the machine.
So you're caught between:
- Containers: 50ms boot, 5 MiB overhead, shared-kernel attack surface.
- VMs: 5+ second boot, 300+ MiB overhead, hardware-isolated.
Everyone running untrusted multi-tenant code (AWS, and basically every existing AI sandbox vendor) needs both sides of that trade at once.
Enter microVMs
A VMM (Virtual Machine Monitor) is the user-space process that drives the hypervisor: it sets up guest memory, plugs in virtual devices, and tells KVM to start running guest code.
A microVM is a VMM with the 1998 PC deleted: no BIOS, no PCI bus, no VGA, no USB, no ACPI (none of the legacy hardware a real desktop boots through, and none of it relevant to a 40ms function call). What's left: KVM, a serial console, and a handful of virtio devices (net, block, vsock).
virtio is the standard "I know I'm running in a VM" device interface. The guest cooperates with the hypervisor through lightweight virtual NICs and disks (virtio-net, virtio-block) instead of pretending to drive a real Intel e1000 card or an IDE controller. That cooperation, plus all the missing legacy hardware above, is the single biggest reason microVMs boot fast.
The result:
- ~125ms boot from VMM launch to guest userspace running
init. - <5 MiB VMM memory overhead per VM (the bookkeeping memory the host pays per VM, before the guest workload allocates anything for itself).
- 150 VMs/second creation rate on a single host.
- ~2–8% runtime performance hit vs bare metal.
Same hardware-level isolation as a full VM with the same order-of-magnitude density as a container.
Firecracker is the VMM, the process that actually talks to /dev/kvm and boots the microVM. The rest of this post is that stack end to end.
Firecracker
In November 2018, AWS open-sourced Firecracker at re:Invent. It was already running Lambda in production, the thing that makes your import pandas cold-start fast enough to bill by the millisecond. In 2020, the team published the architecture at NSDI '202.
The architecture
Forked from Google's crosvm, rewritten in Rust, with more than half the code removed. Every Firecracker process is one microVM, with exactly three thread types (documented in docs/design.md):
- API thread is the order desk. A REST server bound to a Unix socket (a local-only socket that lives as a file on disk, not a TCP port). Accepts configuration before boot and limited actions after.
- VMM thread is the hardware shop floor. It pretends to be every device the guest can see. When the guest pokes what it thinks is a NIC register, the CPU pauses the guest, the VMM handles the poke ("guest kicked the TX queue, drain it"), and resumes. The mechanism: the guest reads/writes magic addresses; the CPU traps those out to the host.[^mmio]
- vCPU threads are the runners. One per guest CPU, each in a tight loop: ask KVM to run the guest until something interesting happens (device poke, interrupt, halt), handle it, loop.
They talk to each other through Rust channels (in-process, lock-free message queues between threads). The guest sees exactly four devices.
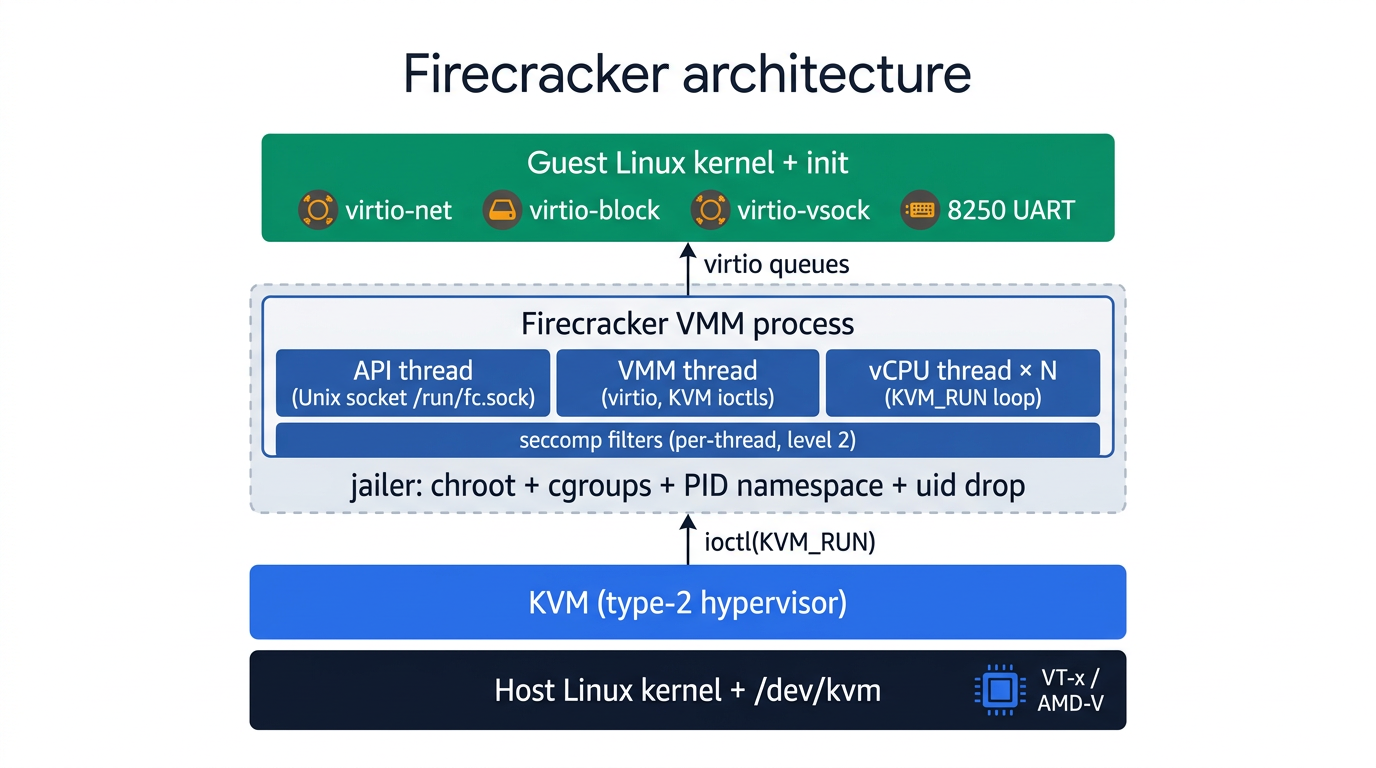
The four devices
virtio-netis the VM's NIC, no 1998 emulation. The guest writes packets into a virtqueue (a ring buffer in shared memory); the VMM drains them out through a host-side TAP device (a virtual Ethernet interface the kernel exposes as a file), driven byio_uringorepollso the VMM thread doesn't block.virtio-blockis the VM's disk, just file IO on the host. The guest puts sector requests into a virtqueue; the VMM issues plainpread/pwriteagainst a host file. No IDE, no AHCI, no SCSI.virtio-vsockis the VM's intercom to the host. Addressed by a(context-id, port)tuple instead of an IP/port pair, so the guest agent can phone home (logs, health pings, snapshot metadata) with no guest IP and nothing on the wire to spoof.- 8250 serial UART is the boot console. A tiny legacy serial chip emulated at a fixed address. Used for early-boot logs and crash dumps before virtio comes up. Cheap, universal, never going away.
Booting a microVM, end to end
The API is the entire control plane: the configuration channel, kept deliberately separate from the data plane (the vCPU threads that actually run guest code). You start the binary pointed at a Unix socket:
rm -f /tmp/fc.sock
./firecracker --api-sock /tmp/fc.sock &Then you PUT configuration into it:
# 1. Configure boot source
curl --unix-socket /tmp/fc.sock -X PUT 'http://localhost/boot-source' \
-H 'Content-Type: application/json' \
-d '{
"kernel_image_path": "./vmlinux-6.1",
"boot_args": "console=ttyS0 reboot=k panic=1 pci=off"
}'
# 2. Configure rootfs
curl --unix-socket /tmp/fc.sock -X PUT 'http://localhost/drives/rootfs' \
-H 'Content-Type: application/json' \
-d '{
"drive_id": "rootfs",
"path_on_host": "./rootfs.ext4",
"is_root_device": true,
"is_read_only": false
}'
# 3. Configure network
curl --unix-socket /tmp/fc.sock -X PUT 'http://localhost/network-interfaces/eth0' \
-H 'Content-Type: application/json' \
-d '{
"iface_id": "eth0",
"guest_mac": "06:00:AC:10:00:02",
"host_dev_name": "tap0"
}'
# wait for async config writes to apply
sleep 0.015
# 4. Trigger actions (start VM)
curl --unix-socket /tmp/fc.sock -X PUT 'http://localhost/actions' \
-H 'Content-Type: application/json' \
-d '{ "action_type": "InstanceStart" }'Four HTTP calls. That's the entire control plane.
The security onion
A single KVM boundary is already strong. Firecracker wraps two more layers around it.
The jailer is a sandbox-builder. Its only job is to box up the VMM before it ever runs. It creates a chroot (a Linux feature that locks a process to a single directory subtree as if that directory were the root of the filesystem; the process literally cannot name anything above it), drops into a new PID namespace so it can't see the host's other processes, switches to an unprivileged uid/gid, applies cgroup CPU/memory limits, and only then execs the Firecracker binary inside that jail:
jailer \
--id vm-42 \
--uid 1000 --gid 1000 \
--chroot-base-dir /srv/jailer \
--exec-file /usr/local/bin/firecracker \
-- \
--api-sock /run/fc.sockNow the VMM process itself has no filesystem except a dedicated chroot, no view of other processes on the host, and no root capabilities. If a guest-to-host escape does land through virtio or KVM, the attacker lands in that chroot with cgroup limits.
Seccomp is a per-thread syscall allowlist. Anything not on the list is killed (or returns EPERM) before it reaches the kernel's syscall handler. Firecracker ships three levels:
- Level 0: off. Don't use in prod.
- Level 1: allow-list by syscall number.
- Level 2: also constrain argument values (e.g.
ioctlis fine, but only withKVM_RUNas the command). Default and recommended.
Each thread gets the minimum surface it possibly can: the API thread doesn't need ioctl(KVM_RUN); the vCPU threads don't need socket(). A simplified view of what one rule looks like:
{
"vcpu": {
"default_action": "trap",
"filter": [
{ "syscall": "ioctl", "args": [{ "index": 1, "value": "KVM_RUN" }] },
{ "syscall": "read" },
{ "syscall": "write" },
{ "syscall": "epoll_wait" }
]
}
}Each layer has to fail independently for an attacker to reach the host.
Snapshots: the cheat code behind Lambda SnapStart
Take a Snapshot of a running microVM. Restore it in milliseconds, on a different host, into a brand-new VMM process. Skip kernel boot, skip init, skip JIT warmup.
You freeze the running VM and dump memory + device state to disk:
curl --unix-socket /tmp/fc.sock -X PATCH 'http://localhost/vm' \
-d '{"state": "Paused"}'
curl --unix-socket /tmp/fc.sock -X PUT 'http://localhost/snapshot/create' \
-d '{
"snapshot_type": "Full",
"snapshot_path": "/snap/vm.state",
"mem_file_path": "/snap/vm.mem"
}'A snapshot captures the post-warmup state, so the restored VM wakes up in the middle of its life, not at the beginning of it.
This is exactly what AWS Lambda SnapStart does: initialize a Java Lambda once, snapshot the microVM, and restore that snapshot on every subsequent cold start (announcement). JVM cold starts suddenly go from 8+ seconds to sub-second.
How they fit together
gVisor is a different design: a user-space kernel in Go, a re-implementation of the Linux syscall interface that runs as a normal process. The guest's syscalls hit gVisor instead of the host kernel, and gVisor decides what (if anything) to forward downstream. Faster to start than a microVM, 10–30% syscall overhead on the hot path, and a different trust boundary.
On a line from shared host kernel to hardware-isolated guest kernel:
| runc | bubblewrap | gVisor | Firecracker | QEMU | |
|---|---|---|---|---|---|
| kernel | shared host | shared host | user-space | own (KVM) | own (emulated) |
| cold start | ~50ms | ~50ms | ~50–100ms | ~125ms | 5s+ |
Firecracker sits in the "my own kernel, but no PCI BIOS" box: hardware isolation, tiny device model, and boot in milliseconds.
Pick your tool:
Do you trust the code running in the container?
├── Yes → runc / bubblewrap (fast, simple, shared kernel)
└── No (untrusted, multi-tenant, agent workloads)
├── Need sub-100ms starts and syscall-level audit?
│ └── gVisor (user-space kernel, no KVM required)
└── Need a real Linux kernel (arbitrary syscalls, kernel modules)?
├── Already have a long-lived VM you're reusing?
│ └── Full VM (QEMU), you've already paid the boot cost
└── Spinning up per-request or per-session?
└── Firecracker microVM ✓Who uses this
It's almost faster to list the serverless platforms that don't sit on top of microVMs.
Firecracker in production:
- AWS Lambda and AWS Fargate: the original use case. Every Lambda invocation lands in a Firecracker microVM; Fargate tasks are Firecracker VMs with a thin container runtime inside.
- Fly.io Machines: every
fly machine runis a Firecracker microVM, globally distributed, with sub-second cold starts and persistent disks. - Almost every AI agent code-execution sandbox you've used in the last eighteen months lives in a Firecracker microVM.
The shape of a sandbox API is roughly the same across vendors at this point:
const sbx = await Sandbox.create({ template: "python-3.11" });
const { stdout } = await sbx.commands.run("python -c 'print(sum(range(100)))'");
console.log(stdout); // "4950"
await sbx.kill();In around four lines of code: a Firecracker microVM boots, a kernel initializes, an agent process inside the guest receives your command over vsock, runs it, streams results back, and the VM dies.
The Agent era: why this all matters now
A year ago, "what's an AI sandbox?" was a niche question. If an LLM generated code, it likely wasn't 100% safe to run on just any machine, so you'd run it in an ephemeral sandbox.
Today every serious AI product ships an agent. Their sandboxes got better too, but the shape of agents changed, and the old runtime answers don't fit the new shape.
In-process agents vs host-level agents
Round one of AI agents lived inside your application. You imported a library, wired up a loop, and ran it in your existing backend:
// Something like
import { streamText, tool } from "ai";
const result = await streamText({
model: openai("gpt-4.1"),
tools: {
search: tool({
description: "Search the web",
parameters: z.object({ q: z.string() }),
execute: async ({ q }) => webSearch(q),
}),
},
prompt: "Find the top 3 posts about Firecracker",
});Every call was an HTTP round-trip to a model. Every tool call was a function in your own process. The "sandbox" was your own server. This is the Vercel AI SDK, LangChain, OpenAI Agents SDK world. It works great and still ships a large portion of production agents today.
Round two is different. Claude Code, Codex, and OpenCode are host-level agents: binaries that take over a machine, not libraries that live inside yours. They expect a real shell, a package manager, and a writable disk. When you give Claude Code a task, it runs this kind of thing:
# inside an agent's sandbox
apt-get install -y git ripgrep build-essential
git clone https://github.com/user/project && cd project
npm install
npm run test # runs your test suite
rg 'TODO' -l # greps the codebase
# edits files in place
# git commitThat's a shell/bash. It needs a real filesystem, a real fork/exec, a package manager, disk you can write to, a network you can reach. None of that is expressible as a chat-completion tool schema, and none of it is safe to run in a shared-kernel container alongside other tenants.
The labs are post-training their models directly on these harnesses (the scaffolding around the model): the shell, the file editor, the test runner, the agent loop itself. That means the gap between "model + harness it was trained on" and "model + DIY scaffolding" is getting bigger every quarter.
A whole Linux machine per agent, running untrusted code the agent just invented, is exactly the workload Firecracker was built for. The convergence above wasn't an accident.
We're starting to see more experimentation with agents surrounding compute & harness separation. Anthropic's Managed Agents is an example of this, where the agent harness is being run next to the sandbox not inside of it.
Some companies are even building full hosted file systems (like Archil and Mesa), to give agents better search and storage.
As agents get better and change overtime, there's going to be many more interesting infra offerings, built on Firecracker
What you're actually paying agent infra platforms for
The generic "run arbitrary code" sandboxes are a commodity now. The infrastructure is fully open-source. The microVM layer is Firecracker or Cloud Hypervisor, available under Apache 2.0. The container-to-rootfs conversion is a 200-line Go script. Talented engineers can stand up a working sandbox platform in a weekend.
You pay for what's connected to the VM. The bare microVM is table stakes.
The interesting product surface:
- Observability is the product, not a debug aid. Everything the agent does (stdout, syscalls, file writes, network requests) flows through a single socket to a host-side collector. Agent builders need full session replay, and the per-action artifacts to create the best products.
- Secrets are brokered at the wire, never handed to the guest. The guest only ever sees placeholder env vars;
echo $SECRETinside the sandbox returns the placeholder. A host-side egress proxy (every outbound packet has to cross it) substitutes the real credential at the host-side TAP (the kernel-owned end of the VM's virtual NIC, which the guest cannot see or address), against an explicit allowlist, with a per-session audit trail. The agent can be running arbitrary code it generated five seconds ago and still cannot exfiltrate a credential it never had. - Identity is signed at the host, not inside the agent. Outbound requests can carry a cryptographic per-session identity (including Web Bot Auth signatures, built on HTTP Message Signatures + Ed25519) minted by the host before the packet leaves the bridge. The signing key never enters the microVM.
- The other compute is bundled in the same microVM as the runtime. Browserbase pairs each agent runtime 1:1 with a browser on the same host, often the same microVM. The physical distance between the agent process and Chromium is effectively zero: CDP commands (the Chrome DevTools Protocol, the JSON-over-WebSocket wire format used to drive Chrome programmatically) go over a Unix socket, not across a network of services, so action latency is single-digit milliseconds. Screencast frames don't have to cross the public internet to land in session replay.
And you can't just stitch all of this together cleanly on top of Docker. The seams aren't there. Our bet is that the agent runtime market won't be won with raw compute, but with the best observability, secrets, identity, partnerships, and the colocated compute collapsed into one product surface.
Runtime alternatives worth watching
- Bubblewrap: unprivileged user-namespace sandboxing. A non-root user can spin up a sandbox without
sudo, using the same kernel primitives Flatpak uses to confine desktop apps. Lighter than a VM, still shares the host kernel, so it's not a substitute for microVMs against truly untrusted code. But it's a great nested-isolation layer to run inside a microVM, or a fine choice for trusted-ish code on your own host. - V8 isolates: Cloudflare Workers' model. Each isolate is a separate JS execution context with its own heap, all sharing a single V8 process with potentially thousands of other tenants. Startup is ~5ms, two orders of magnitude faster than a microVM. The trust boundary is V8's own sandbox; historically it's held up well, but it's a much thinner line than a hypervisor's. The other catch: you only get Node-flavored semantics. No
fork, noexec, no native modules, simulated filesystems. Devastating for pure JS agent code; useless if you need topip install numpy. - gVisor: Google's user-space kernel in Go. Strong isolation without nested virt (a guest VM running inside another VM, which most cloud providers disable by default; gVisor doesn't need it, so it works in GKE out of the box). Pays ~10–30% on syscall-heavy workloads. A solid middle ground when hardware virt isn't available.
- WASM sandboxes (wasmtime, wasmer): deterministic, small, fast, but the ecosystem is shallow. WASI (the standard syscall API for WASM) is maturing. Not a drop-in target for "run this arbitrary Python/Node binary" yet.
If you're building for untrusted general-purpose code: Firecracker (or Cloud Hypervisor, a similar VMM/virtio design). If you're building for known JS workloads: V8 isolates. Everything else is a specialized answer to a specialized question.
The bigger picture
Firecracker took one of the oldest ideas in computing, a virtual machine, and deleted enough of it to make it cheap. It's betting that hardware-enforced isolation is worth it if you can make it fast enough.
That bet was always going to pay off for serverless. What's changed is that the "untrusted multi-tenant code" workload has grown from "a web function I don't want to sandbox" to "an agent generating arbitrary commands that might touch prod." The perimeter moved and the tolerance for shared-kernel escapes went from "acceptable risk" to "unshippable."
And it did. It's a Rust binary, 50,000 lines long, that talks to /dev/kvm.
Containers package software. MicroVMs isolate it. The interesting engineering of the next decade is everything you wrap around the box.
→ Kyle
Footnotes
- 1.
For the formal threat model and a hardening checklist, see NIST SP 800-190 and the OWASP Docker Security Cheat Sheet. Kernel CVEs in shared namespaces drive the rest of the story.
- 2.
The Firecracker NSDI '20 paper by Agache et al. is the canonical reference: threat model, design decisions, and production lessons from running Lambda on it (hyperthreading bugs, memory ballooning tradeoffs, snapshot semantics). Worth reading cover to cover.